Chức năng này được thiết kế để cho phép người dùng tạo các quy tắc nhận thông báo khi trạng thái của các máy ảo (VM) vượt quá hoặc thấp hơn các ngưỡng cụ thể. Các tài nguyên có thể được giám sát và thông báo bao gồm:
- CPU Usage.
- Memory Usage.
- Free Disk Space.
Những người nhận sẽ nhận thông báo khi cảnh báo được kích hoạt.
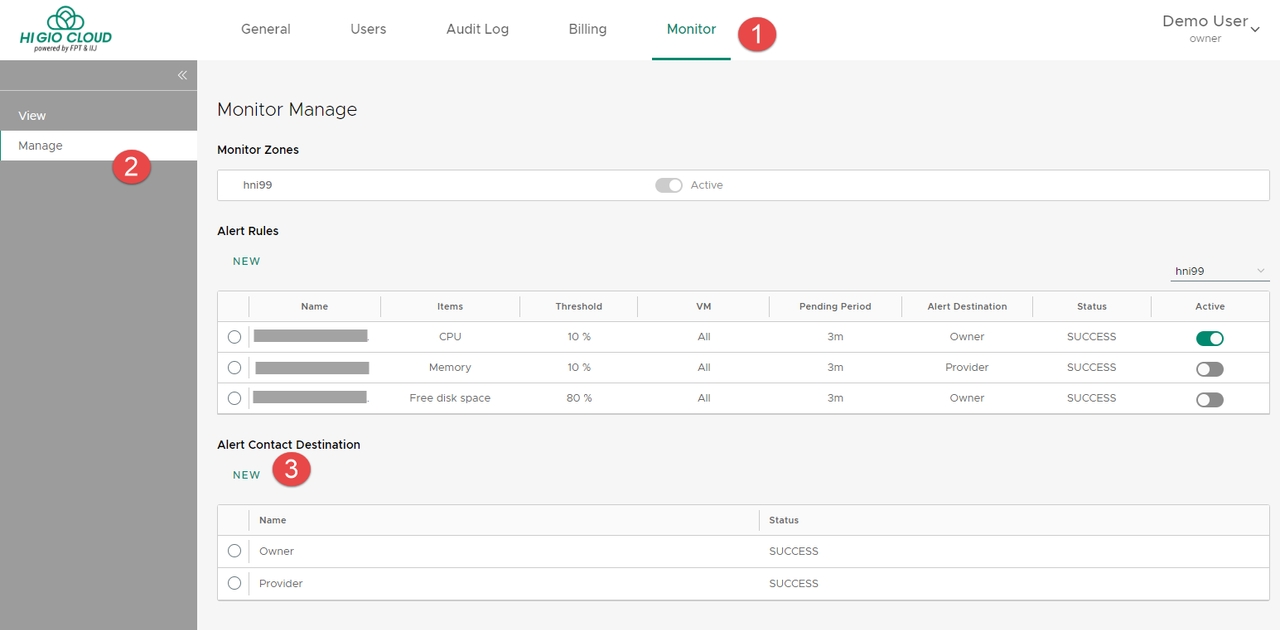
Đăng nhập vào HI GIO cloud > Monitor.
Chọn Manage, và chọn NEW bên dưới phần Alert Contact Destination.
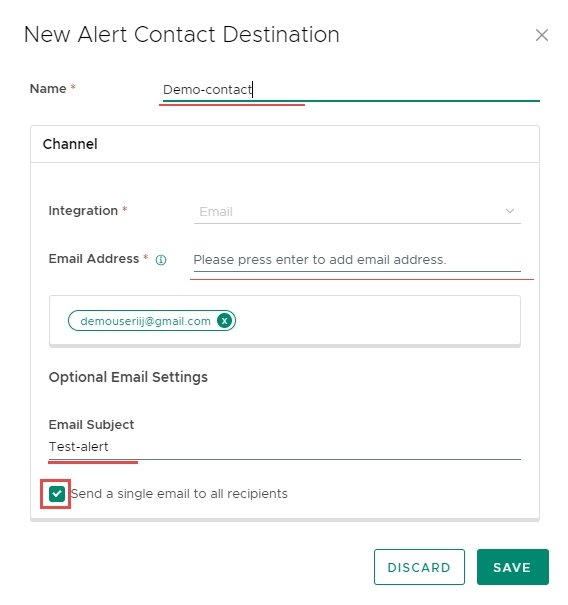
Một cửa sổ mới cho Alert Contact Destination sẽ mở ra. Điền thông tin liên hệ vào cửa sổ này > SAVE.
** Vui lòng thêm no-reply-iam@higiocloud.vn vào email whitelist.
Giải Thích Các Trường Yêu Cầu:
Name: Tên của điểm đến thông báo.
Integration: Kênh mà người dùng có thể nhận cảnh báo. Trong phiên bản này, chỉ có 1 kênh có sẵn: Email.
Email Address:
Địa chỉ email của những người sẽ nhận email cảnh báo.
Bạn có thể thêm nhiều địa chỉ email, nhưng chỉ thêm 1 email mỗi lần. Sau khi nhập đúng địa chỉ email và nhấn phím Enter, địa chỉ email sẽ được thêm vào khu vực văn bản bên dưới, và bạn có thể thêm email khác.
Email Subject: Tiêu đề của email cảnh báo.
Send a single email to all recipients check box:
Nếu chọn, 1 email sẽ được gửi đến tất cả người nhận. Tất cả người nhận sẽ được hiển thị trong trường “To”.
Nếu không chọn, mỗi người nhận sẽ nhận một email riêng biệt >> chúng ta sẽ không biết ai nhận được email thông báo.
Một quy tắc cảnh báo là cấu hình xác định các điều kiện khi nào một cảnh báo sẽ được kích hoạt.
Đăng nhập vào HI GIO cloud > Monitor.
Chọn Manage, và chọn NEW dưới phần Alert Rules.
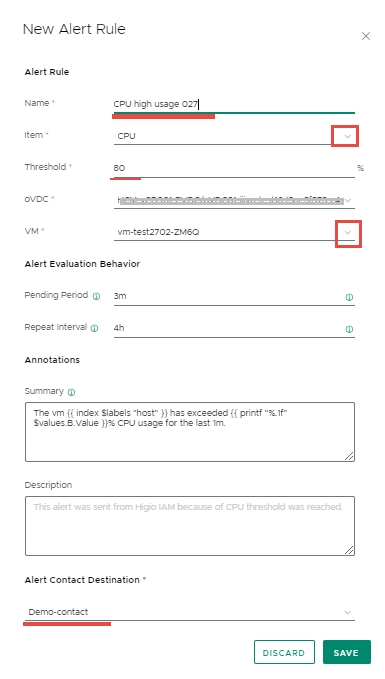
Cửa sổ New Alert Rule sẽ mở ra. Điền thông tin vào cửa sổ này > SAVE.
Giải Thích Các Trường Yêu Cầu:
Name: Tên của quy tắc.
Item: Tài nguyên sẽ kích hoạt cảnh báo. Ví dụ, CPU.
Threshold: Chỉ định các giá trị hoặc phạm vi cụ thể để kích hoạt cảnh báo. Ví dụ, 90% (nghĩa là nếu việc sử dụng CPU vượt quá 90%, cảnh báo sẽ được kích hoạt).
oVDC: Chỉ định oVDC.
VM: Chỉ định VM sẽ kích hoạt cảnh báo. Hộp chọn sẽ chứa tất cả các VM trong oVDC và lựa chọn /.*/ có nghĩa là chọn tất cả các VM.
Pending Period:
Thời gian một cảnh báo sẽ ở trạng thái chờ sau khi được kích hoạt.
Trong thời gian này, Grafana sẽ cho phép điều kiện có thể tự giải quyết trước khi coi cảnh báo đã hoàn toàn được kích hoạt hoặc giải quyết.
Tính năng này giúp tránh các thông báo cảnh báo không cần thiết cho các vấn đề tạm thời.
Giá trị mặc định là 3 phút.
Ví dụ, Pending Period = 3m → có nghĩa là nếu CPU vượt quá 90%, hệ thống sẽ chờ 3 phút. Trong 3 phút này, nếu CPU giảm xuống dưới 90%, không có cảnh báo nào được kích hoạt. Cảnh báo chỉ được kích hoạt nếu CPU vượt quá 90% sau 3 phút.
Repeat Interval:
Xác định tần suất hệ thống kiểm tra liệu các điều kiện để kích hoạt cảnh báo có còn thỏa mãn hay không sau khi cảnh báo đầu tiên được kích hoạt.
Nếu các điều kiện vẫn đúng trong các khoảng thời gian này, hệ thống sẽ tiếp tục gửi thông báo vào khoảng thời gian lặp lại cho đến khi điều kiện cảnh báo không còn thỏa mãn hoặc đã được giải quyết.
Ví dụ, Repeat Interval = 4h và điều kiện là CPU vượt quá 90% → có nghĩa là sau khi cảnh báo được kích hoạt lần đầu tiên, hệ thống sẽ tiếp tục kích hoạt cảnh báo mỗi 4 giờ nếu CPU vẫn vượt quá 90%.
Annotation – Summary, Description: Nội dung của email cảnh báo.
Alert Contact Destination: Điểm đến mà cảnh báo sẽ được gửi đến. Hộp chọn sẽ chứa tất cả các điểm đến liên hệ đã tạo.
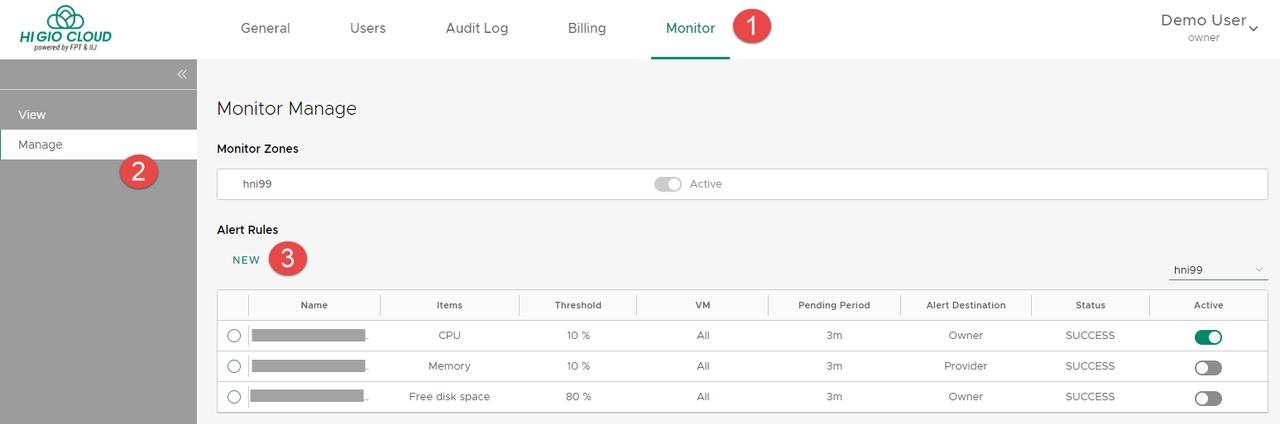
Sau khi hoàn tất, quy tắc cảnh báo sẽ hiển thị như sau:
Chúng ta cũng có thể kích hoạt\hủy kích hoạt các quy tắc trực tiếp từ danh sách này.
Cập nhật trường VM nếu bạn thay đổi tên VM trên portal.
Alert Rule sẽ không tự động cập nhật tên VM trong trường VM.
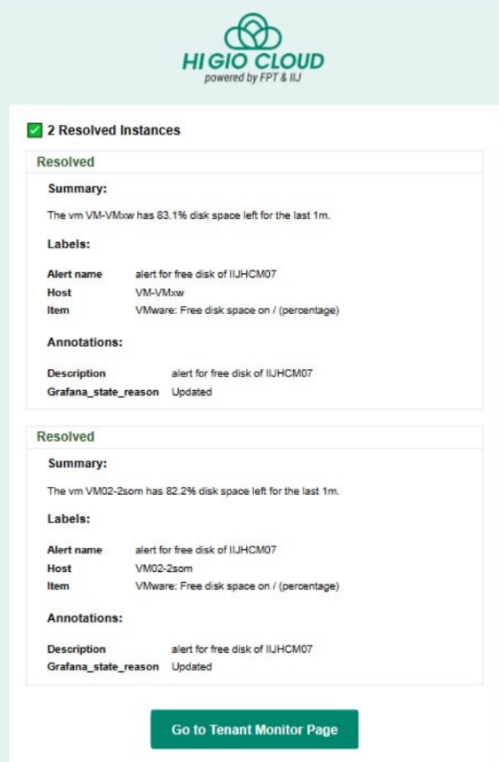
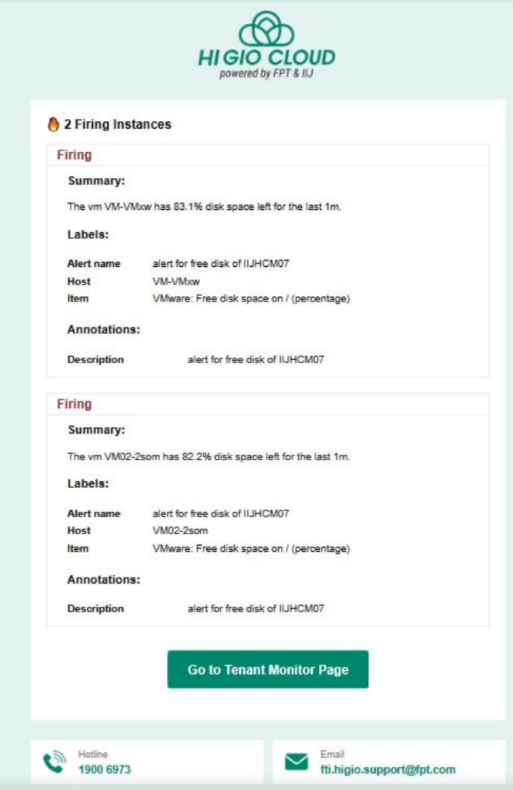
Khi đạt đến ngưỡng được xác định trong quy tắc cảnh báo, bạn sẽ nhận được thông báo qua email - Firing Instance\Resolved Instances.